How Reinforcement Learning(RL Agents) Evolve With Futures Markets
How Reinforcement Learning(RL Agents) Evolve With Futures Markets

By Tyler Archer
February 23rd, 2025
There’s a fundamental problem in algorithmic trading that most developers never solve: the best edges often start as visual insights that are nearly impossible to code.
You watch the futures or stock market for months. You start seeing patterns. You develop an intuition for when certain setups work. Your win rate climbs. Your confidence grows. You’ve found something real. Then you try to automate it.
And everything falls apart.
The Discretionary Trap
Here’s what happens: You sit down to write the rules for your trading bot. You start with the obvious stuff:
“When price crosses above VWAP…”
“And the oscillator is below 30…”
“And volume exceeds the 20-period average…”
You backtest it. The results are… fine. Not great. Definitely not as good as your manual trading. So you add more rules. More indicators. More conditions. The code gets longer and more complex, but the performance doesn’t improve. Sometimes it gets worse.
The problem isn’t that you’re a bad coder. The problem is that you’re trying to translate visual pattern recognition into Boolean logic. Your brain doesn’t actually make trading decisions based on “IF/THEN” rules. It recognizes patterns holistically—shapes, relationships, context, timing. When you try to decompose this into discrete conditions, you lose the essence of what makes the pattern work.
This is why most trading bots fail in the futures or stock markets. They’re optimizing the wrong thing. They’re trying to replicate your rules when they should be replicating your recognition.
The Three-Stage Pipeline | Futures or Stock Markets
After years of wrestling with this problem, I’ve developed a pipeline that actually works. It has three distinct stages:
Stage 1: Visual Discovery
This is where discretionary trading belongs. You need to watch the market, take trades, and discover what works. No shortcuts here—this is pattern recognition in its purest form.
The key is to be systematic about your observation:
- Trade during consistent time windows
- Use identical chart setups every session
- Journal not just what you did, but what you saw
- Note the visual cues that triggered decisions
You’re not trying to trade randomly and “get lucky.” You’re conducting structured observation to discover repeatable patterns. Think of it as fieldwork, not gambling.
Stage 2: Systematic Codification
Once you’ve identified patterns that work, the next challenge is codifying them without destroying them.
This is where most traders fail. They try to write “IF condition A AND condition B THEN enter trade” and wonder why their bot performs worse than their discretionary trading.
The trick is to code the conditions for pattern recognition, not the pattern itself.
Instead of:
IF price > VWAP AND RSI < 30 THEN buy
Think:
WHEN these market conditions exist,
AND this specific price structure is present,
THEN this pattern is ACTIVE (not "take the trade")
You’re building a detection system, not a decision system. The difference is crucial.
The systematic rules should answer: “Is the pattern present?” Not: “Should I trade?”
Stage 3: RL Agent Training
This is where reinforcement learning becomes powerful—and why it’s different from traditional algorithmic trading.
Traditional bots: You program every decision explicitly.
RL agents: You define the environment and let them learn optimal behavior.
Here’s the key insight: RL agents can learn to recognize patterns that you can see but can’t code.
The process:
- Your systematic rules create a “filtered environment” where only valid patterns exist
- The RL agent trains within this environment, learning which actions lead to profit
- The agent develops its own decision-making policy based on reward feedback
- Over time, it learns nuances you couldn’t explicitly program
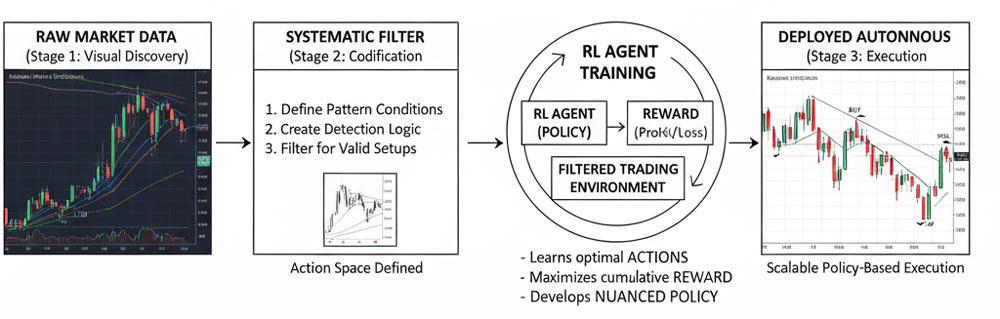
This is fundamentally different from curve-fitting or optimization. The agent isn’t memorizing historical patterns—it’s learning a general policy for pattern exploitation.
Why RL Agents Don’t “Forget” Your Edge
One of the biggest fears with automation: What if the bot stops doing what worked?
With traditional algorithmic trading, this is a real risk. You optimize parameters on historical data, and when market conditions change, the system breaks. It was never actually learning—it was just memorizing.
RL agents solve this through continuous learning architecture:
During development:
- Train on historical data to learn the core pattern
- Validate on out-of-sample data to ensure generalization
- Test in simulation with realistic market dynamics
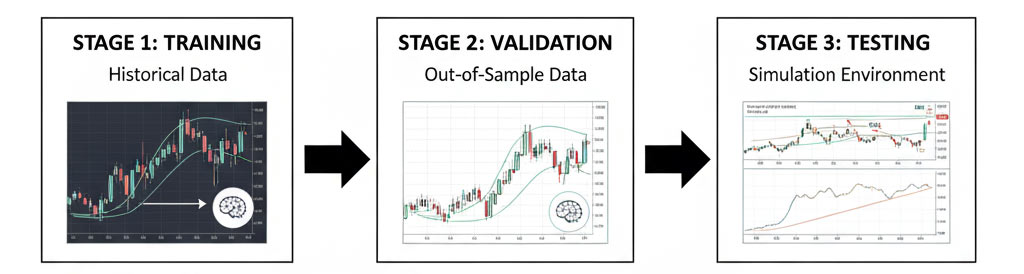
During deployment:
- Agent operates based on learned policy (not memorized rules)
- Can be retrained periodically on new data
- Maintains core strategy while adapting to regime changes

The agent isn’t “forgetting” your edge because it never memorized specific historical instances. It learned the structure of the edge—the general principle that makes the pattern work.
The Visual → Systematic → Autonomous Pipeline
Here’s what the complete pipeline looks like in practice:
Month 1-3: Visual Discovery Phase
- Trade manually during optimal market hours
- Use consistent visual setup across all sessions
- Document patterns that consistently work
- Build conviction through repetition
Month 4-6: Systematic Codification Phase
- Identify conditions that signal pattern presence
- Code detection logic (not decision logic)
- Backtest pattern frequency and basic viability
- Refine detection to reduce false positives
Month 7-9: RL Agent Training Phase
- Create simulation environment with detected patterns
- Define reward structure (profit, drawdown, risk metrics)
- Train agent using modern RL algorithms (PPO, SAC, etc.)
- Validate agent performance vs. manual trading
Month 10+: Hybrid Execution Phase
- Run agent in parallel with manual trading
- Compare decision quality in real-time
- Gradually increase agent autonomy as trust builds
- Maintain ability to override for edge cases
The key is that each stage builds on the previous one. You’re not throwing away your discretionary insights—you’re progressively systematizing them while preserving what makes them work.
Common Pitfalls (And How to Avoid Them)
Pitfall 1: Coding too early
Symptom: You’ve only traded the pattern 10-20 times but you’re already writing code.
Solution: Build conviction first. You need 50-100+ observations before codification.
Pitfall 2: Over-parameterization
Symptom: Your systematic rules have 15+ conditions and 20+ tunable parameters.
Solution: Simplify. If you can’t explain the pattern in 3-4 sentences, you don’t understand it yet.
Pitfall 3: Training on insufficient data
Symptom: RL agent performs great in backtests, terrible in forward testing.
Solution: Need thousands of pattern instances for robust training. If you don’t have this, stay in Stage 2 longer.
Pitfall 4: Expecting perfection
Symptom: Agent doesn’t replicate your exact decisions, so you abandon it.
Solution: The agent doesn’t need to trade exactly like you—it needs to perform like you. Different paths to same outcome is fine.
The Real Goal: Leverage Without Complexity
The ultimate purpose of this pipeline isn’t to replace human judgment entirely. It’s to create leverage.
One human trader can watch one market during specific hours. An RL agent can watch multiple markets 24/7, executing the same pattern recognition principles you discovered.
You’re not trying to build a fully autonomous system that operates in a black box. You’re building a scalable version of your own edge—one that extends your reach without requiring you to stare at charts all day.
The discretionary insight remains yours. The systematic codification preserves it. The RL agent scales it.
What This Looks Like in Practice
I’m currently in the transition between Stage 2 and Stage 3. My systematic rules can detect the patterns I trade manually. I can backtest their frequency and basic performance characteristics. Now I’m building the RL training environment.
The patterns themselves? Those stay proprietary. But the methodology—visual discovery, systematic codification, RL automation—that’s universal. It works for any edge that starts with human pattern recognition.
In six months, I expect to have RL agents executing alongside my manual trading. In twelve months, the agents should handle the majority of execution while I focus on discovering new patterns and refining the existing ones.
The goal isn’t to eliminate the human element. It’s to eliminate the repetitive execution element.
Pattern discovery remains creative and intuitive. But once proven, why not let machines handle the repetitive task of watching for the pattern and executing the trade?
The Broader Implications For Algos & Bots In The Futures or Stock Markets
This pipeline has implications beyond individual trading:
For systematic traders: You don’t have to abandon discretionary insights. There’s a path to systematization that preserves edge quality.
For quant developers: RL offers a middle ground between “code every rule explicitly” and “throw data at a neural network and hope.” You can guide learning while allowing emergent behavior.
For prop firms and funds: This methodology enables scaling human insight without scaling human headcount. One talented pattern recognizer + RL infrastructure = multiple market coverage.
The future of systematic trading isn’t purely quantitative (statistical models on raw data) or purely discretionary (human judgment on every trade). It’s hybrid: human insight, systematically preserved, autonomously scaled.
Getting Started
If you’re interested in building this pipeline for your own trading:
- Start with Stage 1. Don’t skip ahead. You need real, validated patterns before anything else matters.
- Document obsessively. Screenshots, notes, trade logs. Your future self (and your RL agent) will thank you.
- Learn the basics of RL. You don’t need a PhD, but you should understand concepts like reward shaping, policy gradients, and exploration vs. exploitation.
- Build in Python. The RL ecosystem (Stable-Baselines3, Ray RLlib, etc.) is mature and well-documented. Use existing tools rather than building from scratch.
- Be patient. This is a months-long process, not a weekend project. But the result—systematic execution of discretionary insights—is worth the investment.
The discretionary-to-systematic gap is real in the futures and stock markets, but it’s not insurmountable. With the right pipeline, you can preserve your edge while building the automation that scales it.
<—>
Tyler Archer is a systematic futures trader building quantitative systems and RL agents that exploit institutional order flow through visual pattern recognition, machine learning, and deep reinforcement learning.
Developing Next-Generation Quantitative Trading Systems
Developing Next-Generation Quantitative Trading Systems
I'm a systematic futures trader building complete quantitative systems and RL agents that exploit institutional order flow through visual pattern recognition, machine learning, and deep reinforcement learning.